Hello, I am Priyanka Moorthy.
AI Engineer
I build multi-agent LLM systems and the eval layer that keeps them accountable at scale.

I build multi-agent LLM systems and the eval layer that keeps them accountable at scale.
At Espercare, I built a router-orchestrated multi-agent system on Gemini that handles 2–3K queries/day at 92% routing accuracy and ~2s latency — an intent classifier routing across five specialized agents, with out-of-scope blocking and low-confidence escalation to human review. Alongside it, I shipped a grounded-retrieval revenue-code service over a 1.8M-document corpus that automated 98% of daily claim-line coding, replacing ~8 hours of manual work across ~14K line items per day.
Building evaluation infrastructure was as much of the job as building the systems themselves. I designed a continuous eval harness on Vertex AI — pairwise preference scoring, human feedback collection, regression gating, and an LLM-as-judge layer running automated QA across every agent and pipeline. If I had to name the one thing I know how to do that most teams skip, it's this: instrumenting a deployed LLM system so you actually know what it's doing and when it degrades.
Earlier at RedBlackTree Tech, I built OCR + CNN pipelines that cut document processing time by 82% at 0.92 AUC and async distributed inference on RabbitMQ and Celery. My SJSU thesis extended SAM-SLR for continuous sign language recognition — useful training in the gap between benchmark performance and real-world deployment.
On the side, I've been exploring the embodied end of the stack: I trained a 77M-parameter Vision-Language-Action model with cross-attention fusion between EfficientNet-B0 and DistilBERT for multi-task robot manipulation — 22% loss reduction via behavior cloning across pick, push, and place. This is early exploration toward a longer-term interest in robotics, not a current job skill.
My main project right now is an open-source, interactive playground for learning LLM evaluation structured like Brilliant, built around the real tools that run in production. It covers RAG evaluation with RAGAS, human-in-the-loop feedback with Argilla, regression gating and LLM-as-judge with DeepEval and Inspect AI, and preference learning with TRL. The goal is to make the hardest parts of deployed LLM systems learnable by doing, not just reading. It's the project I care most about right now, and it'll be the headline piece on this site when it ships. On the side, I'm running experiments with a VLA model for multi-task robot manipulation — early exploration that points toward where I want to work in two to three years.
My core work is multi-agent LLM architecture — systems where intent classification, specialized sub-agents, function calling, and human-escalation paths compose into something reliable under production load. The Espercare system is the best example: a router directing queries across five sub-agents, blocking out-of-scope requests, and routing low-confidence cases to human review rather than hallucinating answers.
The second thread, and the one I'm building the eval playground around, is evaluation infrastructure: continuous harnesses running pairwise preference scoring, LLM-as-judge, and regression gating automatically. Most teams skip this layer entirely. Building it properly — in a way that surfaces real degradation, not false signals — is harder than the models.
I've done this specifically in healthcare AI — claims processing, revenue coding, structured extraction from UB-04 and HCFA-1500 forms. In regulated contexts where errors carry a direct dollar cost, the discipline around high-confidence extraction, human-review routing, and audit trails that's usually optional becomes mandatory.
The infrastructure layer is real: Vertex AI, Cloud Run, async job systems on RabbitMQ and Celery, Docker, Kubernetes. I'm comfortable with the full path from training to deployment to monitoring not just building models, but keeping them accountable in production.
I'm looking for teams where LLM infrastructure — agent orchestration, evaluation harnesses, reliability at scale — is a first-class concern, not an afterthought.
In rough priority order: applied LLM or agent infrastructure roles at AI-native startups, especially evaluation platforms (Braintrust, Confident AI, LangSmith) or AI infra companies; ML platform or evaluation engineer roles at companies with serious LLM products (Notion, Linear, Cursor, Vercel AI, Together, Fireworks); production ML roles at LLM-first companies in healthcare or other regulated verticals, where my Espercare experience transfers directly; and research engineer roles focused on evaluation infrastructure and tooling around models rather than novel modeling research.
If you're building the systems that make LLM products trustworthy — not just the models, but the harnesses that tell you they're working — reach out.
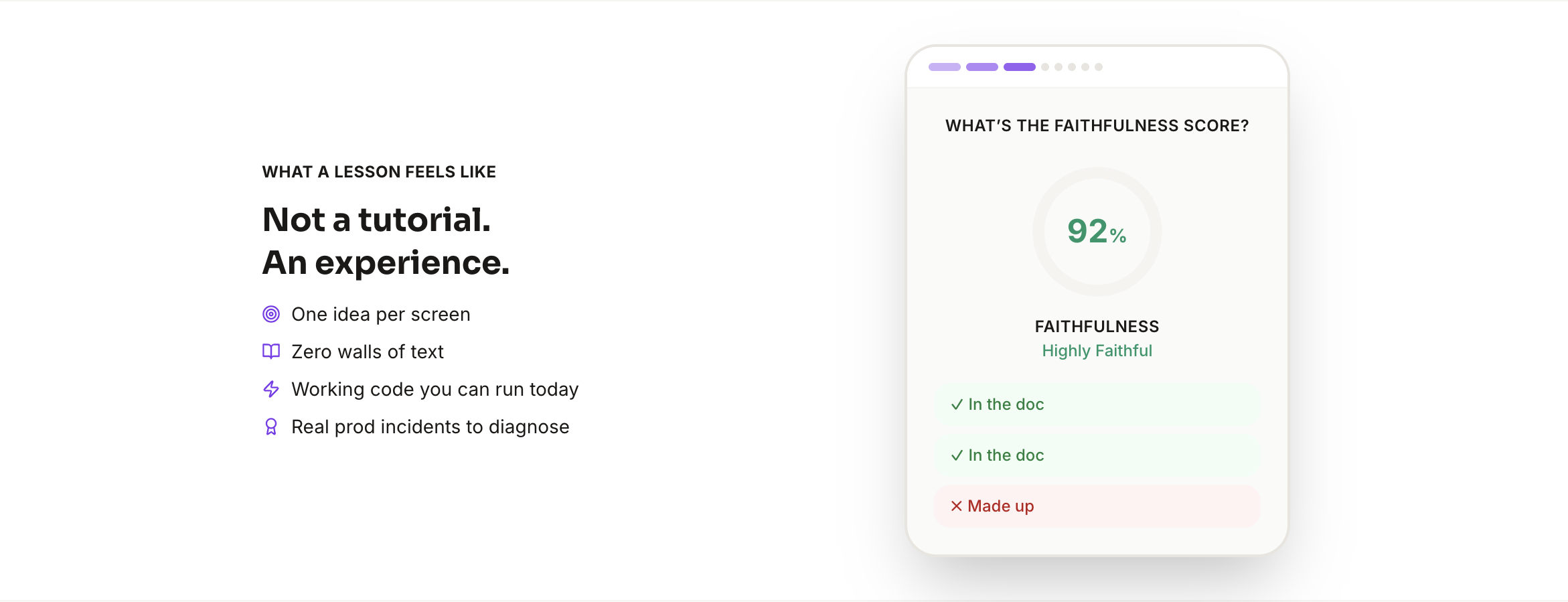
An interactive, open-source playground for learning LLM evaluation by doing structured like Brilliant, built around the tools that actually run in production. Covers RAG evaluation with RAGAS, human-in-the-loop feedback with Argilla, regression gating and LLM-as-judge with DeepEval and Inspect AI, and preference learning with TRL. The architectural bet: real eval is learnable if you show the decision points, not just the framework docs.
Try it live →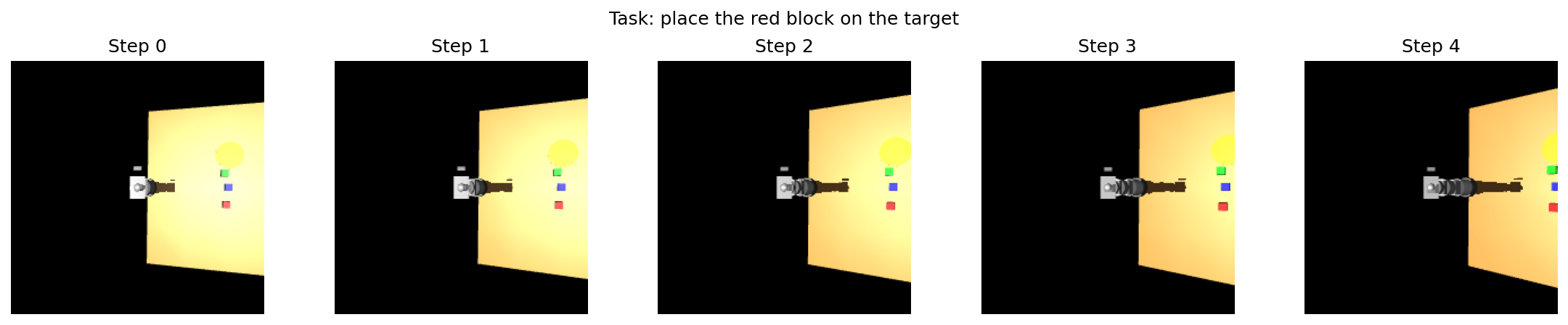
I combined an EfficientNet-B0 vision encoder, DistilBERT, and cross-attention fusion into a 77M-parameter model that maps camera frames and natural-language instructions to robot manipulation actions — cross-attention rather than concatenation forces the model to align visual and language representations before acting. Multi-task behavior cloning across pick, push, and place tasks cut training loss 22% over single-task training.
Read More
My SJSU thesis: extended SAM-SLR for sentence-level continuous sign language recognition by fusing appearance and skeleton keypoint streams. The core challenge was temporal segmentation — identifying sign boundaries within a continuous sequence without explicit markers.

Implemented a DQN agent on OpenAI's continuous mountain car environment — the interesting problem was reward shaping to push the agent past the no-action local minimum where staying still is cheaper than building momentum. Converged in 1,643 episodes.
Read More
Implemented Pix2Pix (U-Net Generator + PatchGAN Discriminator) for line-art to full-color translation on butterfly images. PatchGAN's patch-level adversarial objective was the key choice — it preserves fine texture detail that a global discriminator loses.
Read More
Applied Mask-RCNN to nuclei microscopy segmentation, where instance segmentation matters because individual cell boundaries — not just regions — carry biological meaning. Reached 0.73 mAP on the 2018 Data Science Bowl dataset.
Read More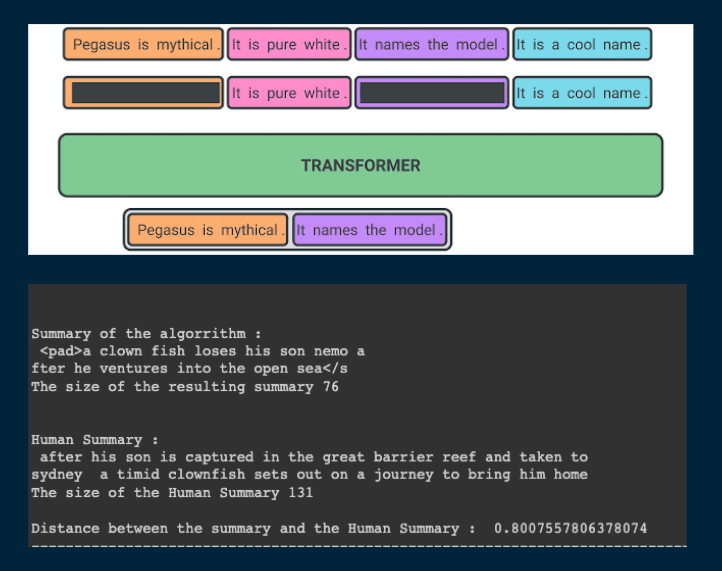
Fine-tuned Pegasus on IMDB plot data for abstractive summarization. Pegasus's gap-sentence pre-training made it the right fit over extractive approaches — it generates coherent summaries rather than lifting phrases verbatim from the source.
Read More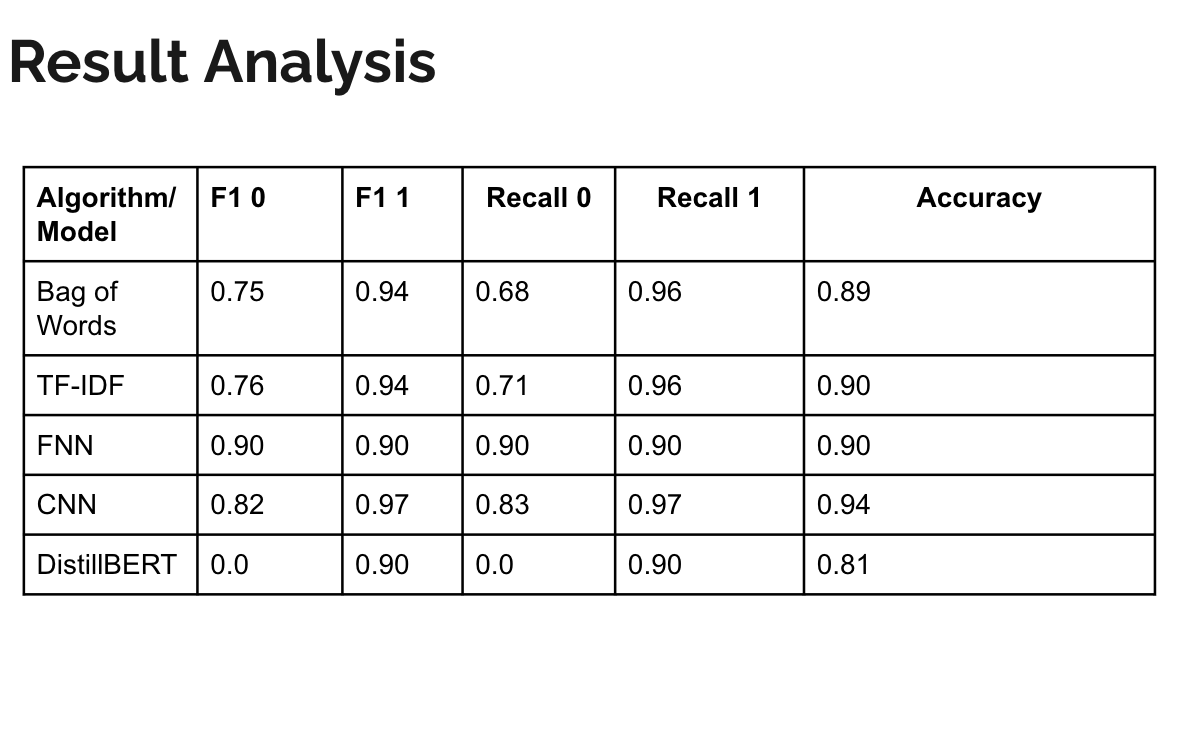
Head-to-head benchmark of FNN, CNN, LSTM, and DistilBERT on Amazon review sentiment classification. DistilBERT outperformed all baselines by a margin that makes the comparison useful as a concrete demonstration of what pre-training actually buys.
Read More
Trained an LSTM on Lo-Fi music data to generate stylistically consistent sequences. More instructive as an exercise in temporal pattern learning than in the output — the gap between statistically likely next-notes and anything a person would want to hear is significant.
Read More